


Physics-based Models or Data-driven Models – Which One To Choose?
Like most contentious questions, the real answer lies in the nuances. This is an important point as engineers run out of runway when it comes to traditional tools and begin to look for alternatives. The purists would say that physics-based models (through physics modeling) are better, as these explain natural phenomena through well-defined mathematics and computational science.
In fact, they would point to the most outstanding scientists in our history as evidence, people who have developed equations that explain the complexities of the natural world, such as the motion of planets. If this is your argument, then, yes, this physics-based modelling approach has stood the test of time. And by contrast, data-driven approaches, which are never too far from the terms artificial intelligence (AI) and machine learning (ML), look almost like the Gen Z of the scientific toolbox.
Figure 1: The Jota Sport team replaced time and cost-intensive testing with data-driven self-learning models to measure and monitor tyre degradation with training data, one of many intractable problems that were solved by their engineers.
However, the world is rapidly changing. Product development, performance, and physical model design are undergoing a massive transformation. Competitive pressure to design feature-rich, accurate, safe, and reliable products is mounting; yet the combination of quality and program schedules cannot be compromised.
In this fast-changing environment, engineers need to utilise all of thier their domain knowledge, innovate with predictive power, and find ways to accelerate product development processes. At the same time, engineers need to accurately understand and predict the performance of newly developed, physically complex systems they are working with on a day-to-day basis.
According to an article in Quanta Magazine, the scientists Roger Guimerà and Marta Sales-Pardo were able to develop an equation to predict when a cell would divide. However, this was not achieved through traditional scientific means. Instead, it resulted from a machine learning algorithm that was trained to develop governing equations based on laboratory test data and field data. When used, the equation delivered excellent predictions of when a cell would divide—they just didn’t know how this specific equation had come about. This leads to the question: Just because we don’t know how an equation that works well came about, should this be grounds to disregard it?
Reality, often in the form of time pressure and business objectives, typically forces such purist thinking to be consigned to the back of the queue. Engineers, increasingly forced to look for cost savings without jeopardising time-to-market, are increasingly open to tools that resolve issues. And, with masses of information collected from years of development and testing, there is often a rich lake of big data untapped.
Hence, they regularly turn to the world of AI and ML to solve the intractable problems they are facing. One issue with physics based simulations and physical models for intractable physics problems is that, when they are available, they require significant processing power to execute as part of a simulation.
 Figure 2: The core of the Kautex engineers’ challenge was to reliably understand the relationship between the properties of the fuel tank, the test parameters, and the resulting sloshing noise – an intractable physics procedure typically requiring multiple physical tests and costly CFD simulations with prototype tank shapes filled at differing levels.
Figure 2: The core of the Kautex engineers’ challenge was to reliably understand the relationship between the properties of the fuel tank, the test parameters, and the resulting sloshing noise – an intractable physics procedure typically requiring multiple physical tests and costly CFD simulations with prototype tank shapes filled at differing levels.
The core of the Kautex Textron engineers’ challenge was to reliably understand the relationship between the properties of the fuel tank, the test parameters, and the resulting sloshing noise—an intractable physics workflow typically requiring multiple physical tests with prototype tanks filled at differing levels. Specifically, in 94% of the simulations conducted by Kautex Textron engineers, Monolith AI Software provided data-driven models of fuel sloshing behaviour to within a 10% margin of error compared to physical tests.
“With Monolith’s machine learning method, we not only solved the challenge, we also reduced design iteration times and prototyping and testing costs. The software reduces design analysis time from days to minutes with improved accuracy. We are thrilled with the results, and we are confident we have found a way to improve future design solutions.”
Dr. Bernhardt Lüddecke, Global Director of Validation, Kautex-Textron
AI To Speed Up Product Development Processes: Data-Driven Model
One application where the classical physics-based approach has run out of steam is in the field of gas and water metres. Flow meters are an essential part of energy provision for commercial and consumer buildings, ensuring that gas delivery is accurately measured and billed. However, one manufacturer had trouble with their CFD models for building meters with enough precision to meet government regulations.

Despite significant investment in simulation, it had proven impossible to find the optimal configuration for the meters. As a result, each meter had to be tested under a wide variety of conditions to calibrate it—a lengthy and costly task. Even a heuristic algorithm provided by an electronics supplier had failed to resolve the issue. The entire programme’s time-to-market goals were significantly at risk.
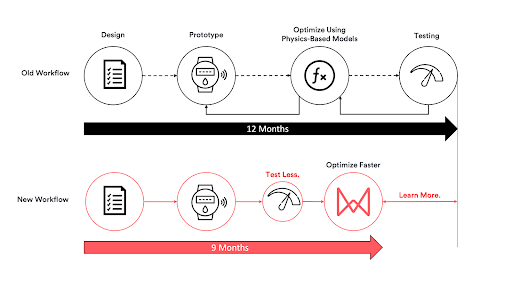 Figure 3: The idealised workflow for a well-understood (linear) problem where time-to-market and testing are minimised by solving known equations which depend on a physics-based model.
Figure 3: The idealised workflow for a well-understood (linear) problem where time-to-market and testing are minimised by solving known equations which depend on a physics-based model.
The silver lining to this challenge came in the form of data—in particular test data—in combination with machine learning algorithms to calibrate the meters.
By uploading, transforming, and feeding the data into the Monolith platform, the ability of our self-learning models to model exceptionally complex non-linear systems delivered a result that reduced testing and accelerated time-to-market while also fulfilling legal requirements.
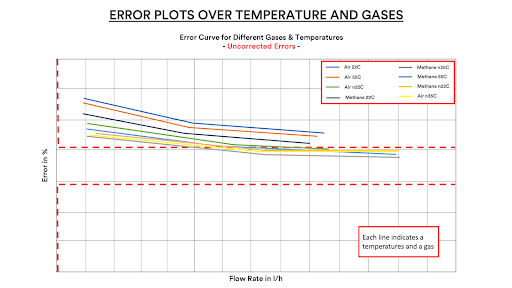
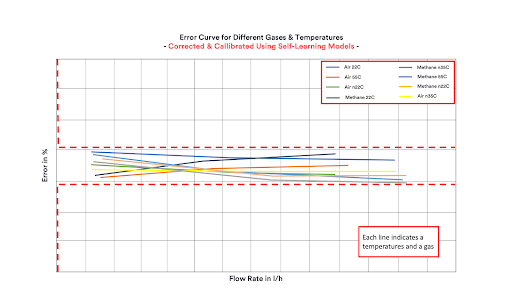
Figure 4 & 5: Using self-learning data-driven models, they not only fulfilled the requirements but also achieved results much faster compared to running time-intensive, tedious, and repetitive test campaigns. At the beginning of each calibration process, the accuracy of the gas meters tends to be outside the legal requirements (top image). Engineers need to calibrate the meters to fall into the red boundaries (lower image). Courtesy: Honeywell.
The key to this impressive feat lies in the challenges of solving the polynomial equations required for the CFD model. These often fail in high-dimensional, volatile systems and don’t tend to improve by providing them with more data and are often based on complex assumptions that might not represent the real-world environment.
After all, it is only a model which has to be fine-tuned by the engineers using the available tool at their fingertips. On the other hand, the neural networks of a self-learning algorithm become more accurate as more data is applied, even in highly stochastic and volatile systems.
Crash testing is one such expense, with leg injuries quantified using the tibia index. Vehicle makers need to ensure that this value stays within specific limits, as defined by governments’ regulations, under various crash conditions. Such results are gathered based upon testing of a particular vehicle model, then archived, never to be seen again.
This is typical of most engineering domains despite product development typically being iterative, building upon existing solutions to create a better one. Work undertaken with a leading vehicle OEM showed that a self-learning model could be built that used data from tibia index crash results.
This allowed changes to be explored that could not be determined through simulation alone due to the intractable nature of the physics. Not only did this allow the final design to reach its optimum faster, but the data also lives on for application in future designs and can be reused for generations of engineers to come.
Conclusion: Physics-Based Model or Data-Driven Model
In conclusion, neither solution is intrinsically better than the other. However, the complexity of the systems we are trying to simulate today has become so overwhelming that a pure physics-based approach often reaches a dead end. Even if it doesn’t, the complexity of the associated calculations can often be so high that advancement is impinged by the time taken to calculate results.
Self-learning AI that creates data-driven models has shown itself capable of reaching beyond that achievable by physics-based models alone. In some cases, physics-based models, sometimes mixed with test data, are still required to generate data to train AI so known limitations can be overcome, indicating room for symbiosis.
In others, the speed with which AI data-driven models can deliver results and predictions simply provides an advantage in increasingly competitive markets. But some cases remain where solutions such as Monolith have been shown as the only way to resolve intractable problems.